The Taskmaster Swear Cloud Appreciation Society
This post contains strong lanuage…reader discretion advised! And this time, I really mean it…

Your Task
Create a swear word cloud which is fit for the Cloud Appreciation Society.
Making it Rain… with Data
We continue to use the profanity based queries we have developed in the following posts (Foulest Mouth of Them All, The Taskmaster’s Potty Mouth).
Some data additional data munging was performed to ensure that all profanities uttered were fully accounted for; namely we have to explode a Python array/list containing profanities through transform and unnest functions.1
The Overall Swear Forecast
We start with the overall forecast for Series 1 to 16 of UK Taskmaster. As you might assume from the task brief, we will be using the visualisation medium of word clouds to show our appreciation to the swear words uttered.
Word clouds are a simple way to visualise word based datasets. We can capture which words are popular and how frequently they are used (more frequent words are larger in font size), and the variety of words in our dataset.
Figure 1: Overall Taskmaster Swear Cloud

Figure 1 indicates that:
FuckandShit(which I will now refer to as Tier1 Swears) are the most uttered swear words in the show as they are largest in font size.- These two words are comparable in size, but
Fuckseems slightly bigger of the two and thus more frequently uttered.
- These two words are comparable in size, but
Hell,Ass/Arse,Christ,Piss(Tier2 Swears) are potential the next most frequently uttered profanities and are all of similar size.- Based on how much smaller these Tier2 Swears are compared to Tier1 Swears, I would assume that Tier2 Swear Words utterance frequency is considerably lower than Tier1 Swears (by many magnitudes perhaps as well).
Damn,Dick,Prick,BastardandBollockmake up a Tier3 Swears which are the next level of font size and frequency.- Based on how similar the font size of the Tier2 and Tier3 Swear Words are, I would assume that the utterance frequencies are similar in magnitude.
- The remaining swear words (Tier+4 Swears) close out our swear word cloud and the variety in profanity. These are uttered in lower frequency and start referring to specific genders and bodily parts (
Bitch,Whore,Wank,Pussy,Cunt).
Our findings are in line with external stuies concerning the most common swear words in the UK (Guardian Article):
FuckandShitare the two most commonly used swear words in the UK.- It is hypothesised that they are frequently used “to emphasis a point in conversation or to build social bonds, rather than with specific intent to cause offence”.
- This supports our Tier4 Swears insights; these swears are used in specific contexts and thus not likely to be used frequently.
- In my opinion, these swears also have a stronger intention to offend behind them (more than
FuckandShitat least), and are more directed to an individual or group of people which may also contribute to their low utterance frequency. - Despite initial appearances, Taskmaster is less about “offending and insulting people” and more “being entertained and laughing at comedians failures (and successes) in inconsequential tasks”.
- In my opinion, these swears also have a stronger intention to offend behind them (more than
The Series Swear Forecast
We have the overall Swear Forecast and insights, but we should also check whether these insights are consistently seen across each series, or if particular series(es) is driving fuck and shit usage.
Figure 2: Taskmaster Swear Cloud by Series
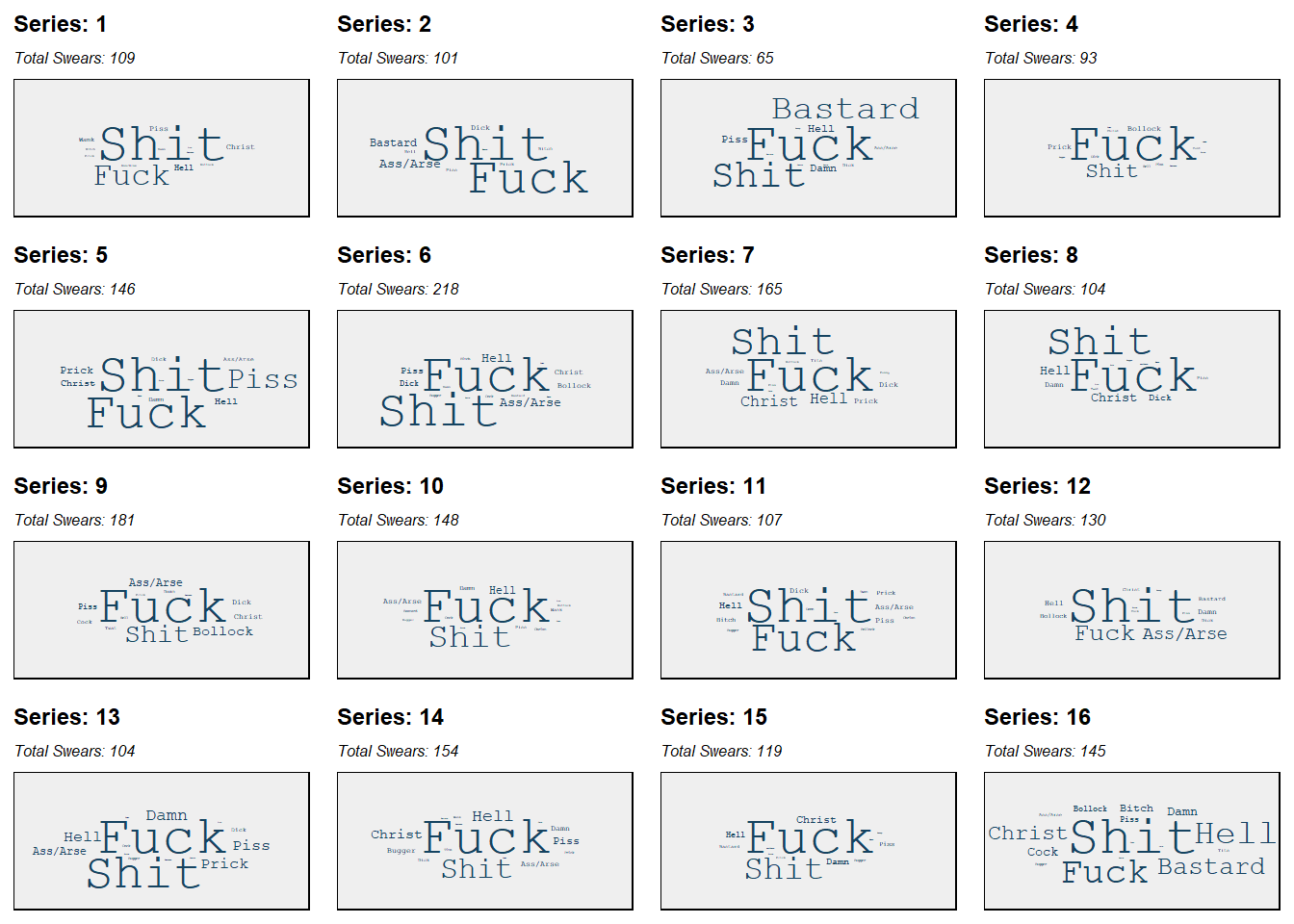
Figure 2 plots word clouds for each series individually and highlights:
ShitandFuckare the most uttered swear words for each individual series, in addition to the overall show level. However, there are some series which are more lovers ofshits thanfucks and vice versa.- Lovers of
shits more thanfucks: Series 1, 11, 12, and 16. - Lovers of
fucks more thanshits: Series 3, 4, 7, 8, 9, 10, 14, and 15. - Comparable lovers of
shits andfucks: Series 2, 5, 6, and 13.
- Lovers of
- A wide variety of profanity vocabulary was uttered in Series 16.
Bastard,Hell, andChristare evidently used, and their comparable font size to Tier1 Swears suggests they are uttered with similar magnitude to them (at least in comparison to other series). Bastardis also a noticeable favourite swear in Series 3.- Good to know the impact of Paul Chowdry propogates to the clouds.

Getting My Head out of the Clouds, and Going to the Bar.
This is my first time generating word clouds and I thought I would share my personal experience with them (so far). I am using the ggwordcloud function from the package of the same name to create these plots.
My first attempt at this post also used the wordcloud and wordcloud2 package, before switching to ggwordcloud to stay within the convenient ggplot ecosystem.
I would say that care needs to be taken when creating word clouds. There is a random component when these plots are generated, and certain argument options for ggwordcloud can greatly affect the plots and conclusions we can draw from them, namely the scale argument which represent the (relative) font size of the most and least frequent word.
On many occasions and with certain arguments, words would be excluded from the cloud as they were too big and did not fit on the plotting area. These exclusions would be fine if they were infrequent words, but after some digging around, I later discovered that frequent words (Tier1-2 Swears) were being excluded on some instances. These exclusions are incredibly misleading as to what are the most frequent uttered swear words.
Based on this experience, I would advocate that a barplot2 may be the safer option in displaying the same, if not more, information as that on a word cloud.
Figure 3: Barplot of Swear Word Utterances over Taskmaster Series 1 to 16.
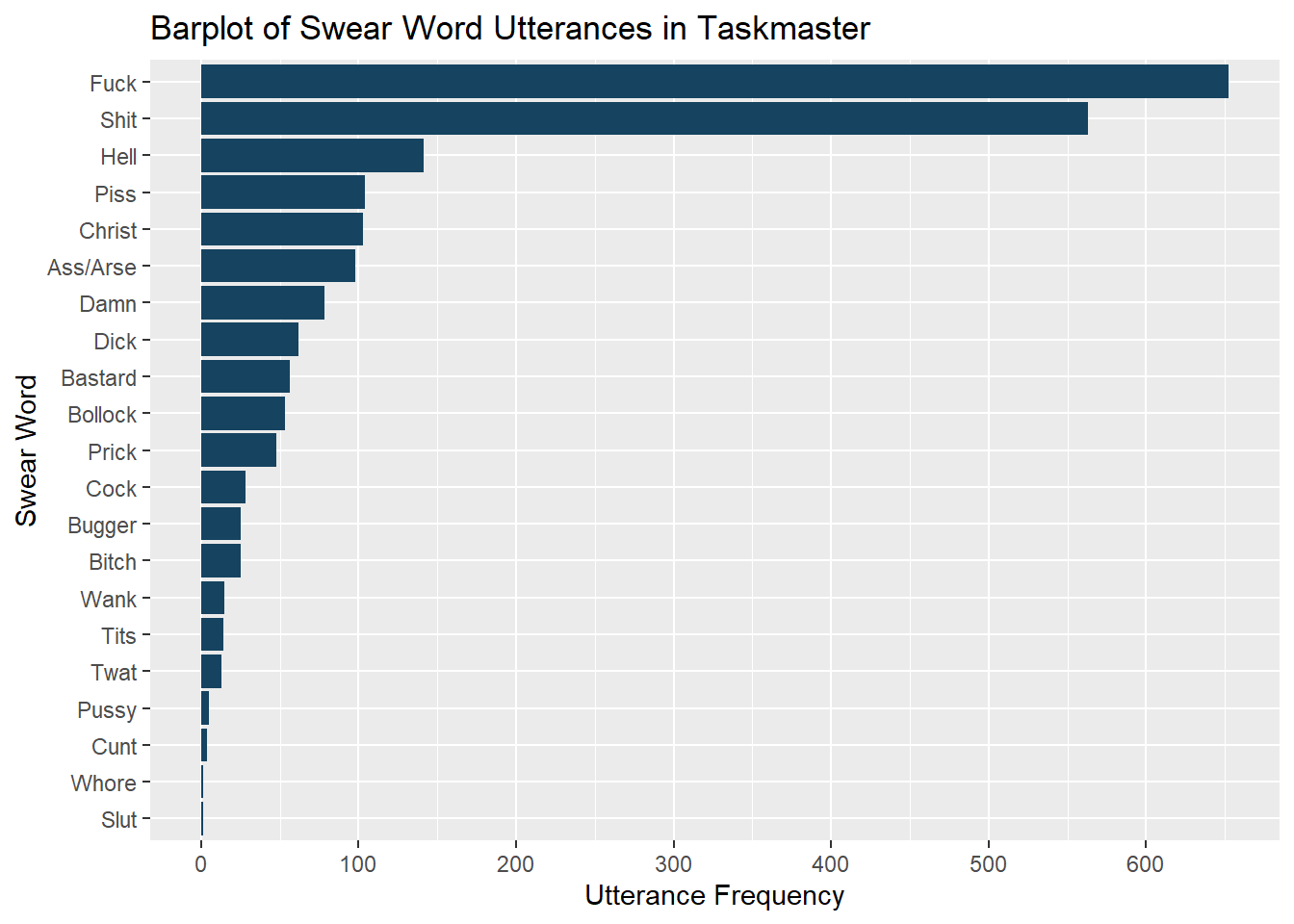
Figure 3 is the barplot equivalent of the word cloud presented in Figure 1. Minimal additional arguments were used in generating the barplot compared to the word cloud. By having the utterance frequency explicitly stated on the graph, we can glean that:
FuckandShitare the two most popular swear words (as also concluded from the word cloud), withFuckbeing the most favoured profanity.- This latter remark was harder to deduce from the word cloud.
- These Tier1 Swears are uttered approximately 6 times more than Tier2 Swears (
Hell,Piss,Christ).- We would not be able to estimate this magnitude from a word cloud directly.
- We are able to clearly distinguish the leading swear words in the Tiers we have created. For example
Hellis the most popular of the Tier2 Swears. - We are able to reassess and redefine our Tier Swear classification, and which profanities belong to it. For example we can clearly deduce that the following Tiers for the lesser uttered profanities.
- Tier4 Swears:
Cock,Bugger,Bitch,Wank,Tits,Twat.- The last three could be their own mid Tier Swears.
- Tier5 Swears:
Pussy,Cunt,Whore,Slut.
- Tier4 Swears:
But I get it, word clouds are very in vogue and are certainly less intimidating and overwhelming for those who do not enjoy data or numbers. Ultimately, I suspect that word clouds suffer the same fate as pie charts which are notorious for being bad graphs for conveying information (one of many pie chart criticism articles).
But then again, a “Bar Appreciation Society” wasn’t presented as a prize task in the show so it doesn’t fit in with the narrative of this post. I’m sure a Bar (or Pub, Drinking Establishment) Appreciation Society does exist though and may be even more well received by the Taskmaster than the Cloud Appreciation Society.
What Have we Learnt Today?

I couldn’t give a Fuck or Shit about what we’ve learnt today; stop being lazy and do your own conclusion summary for once!
These Fucks and Shits have all been used by each series of Taskmaster as popular profanities to use and are forecasted to be in horizon for the foreseeable future. There will occasionally be showers of Hell, Piss, Christ and Arses and other colourful profanities, but there will (likely) always be a Fuck and Shit foundation.
Currently, each record row of the
profanitytable represents a single quote from a speaker in which at least one profanity was uttered. These individual profanities are stored in a Python array/list object with each element in the array representing a different profanity utterance. This data design allows for a quotes in which multiple profanities are uttered. For example, if Greg exclaimed"Fuck Off You Little Shithead", the Python array would be["Fuck", "Shit"]since two profanity based words were uttered in this single exclaimation. We need to “explode” this single record entry so thatFuckandShitare captured as two different records for this single quote. This exploding is achieve throught thetransformandunnestfunctions in the librarydplyr.↩︎Other plots are available… Particularly those which are equally simple, but still effective, as bar plots.↩︎